在 Spring AI Alibaba 程序中,我们可以直接使用本地程序调用百炼平台的云知识库,实现知识库文档解析、分块、向量化存储等一条龙服务。
这样,开发者就不用本地部署搭建向量数据库、不用进行复杂的文档处理,以及开发文档管理等业务功能了,可以大大提升开发效率,非常哇塞。
那问题来了,如何对接百炼平台的云知识库呢?
本文我们基于最新版正式版 Spring AI Alibaba 和百炼平台带着大家一起操作一下。
1.百炼添加数据和知识库
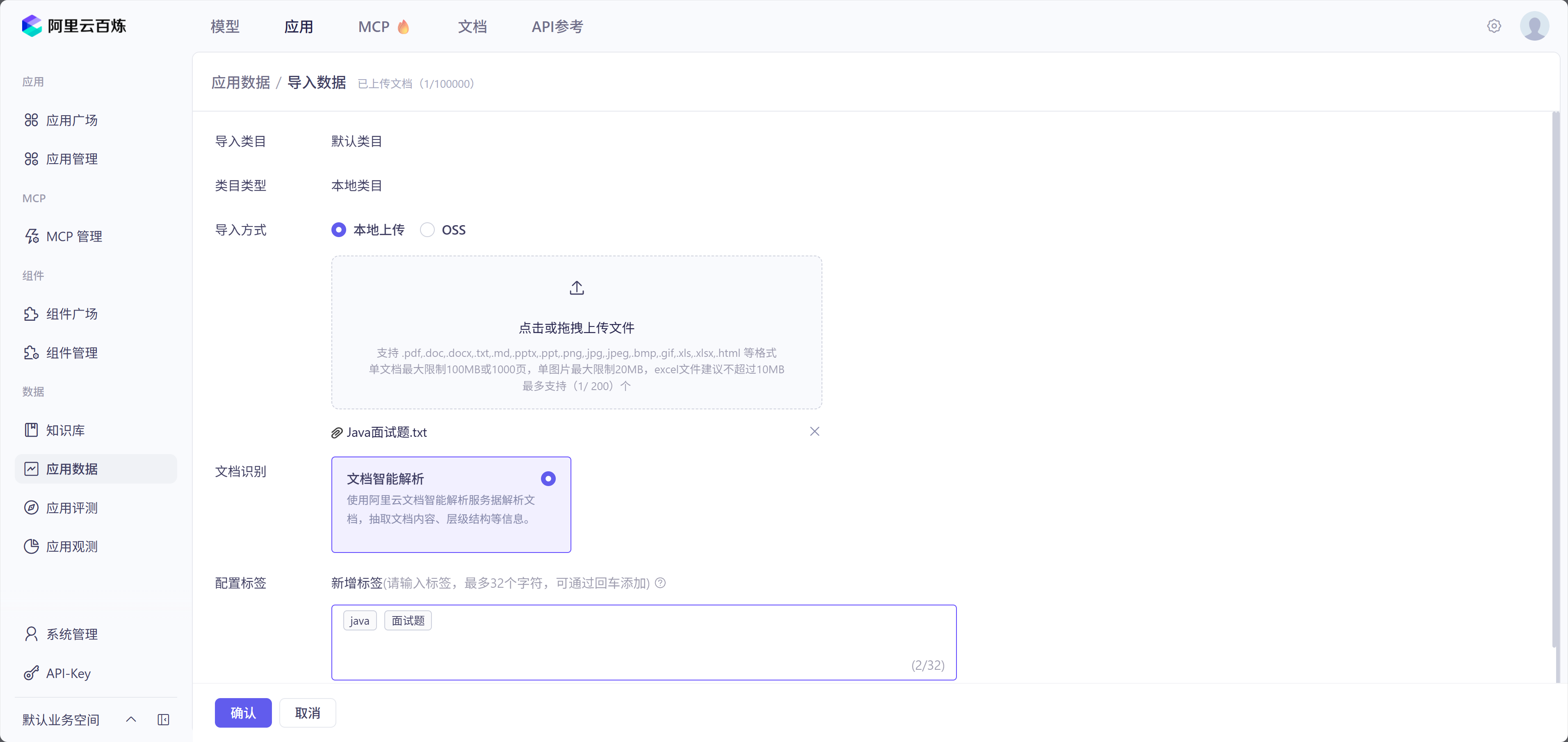
- 导入数据(https://bailian.console.aliyun.com/console?tab=app#/data-center):

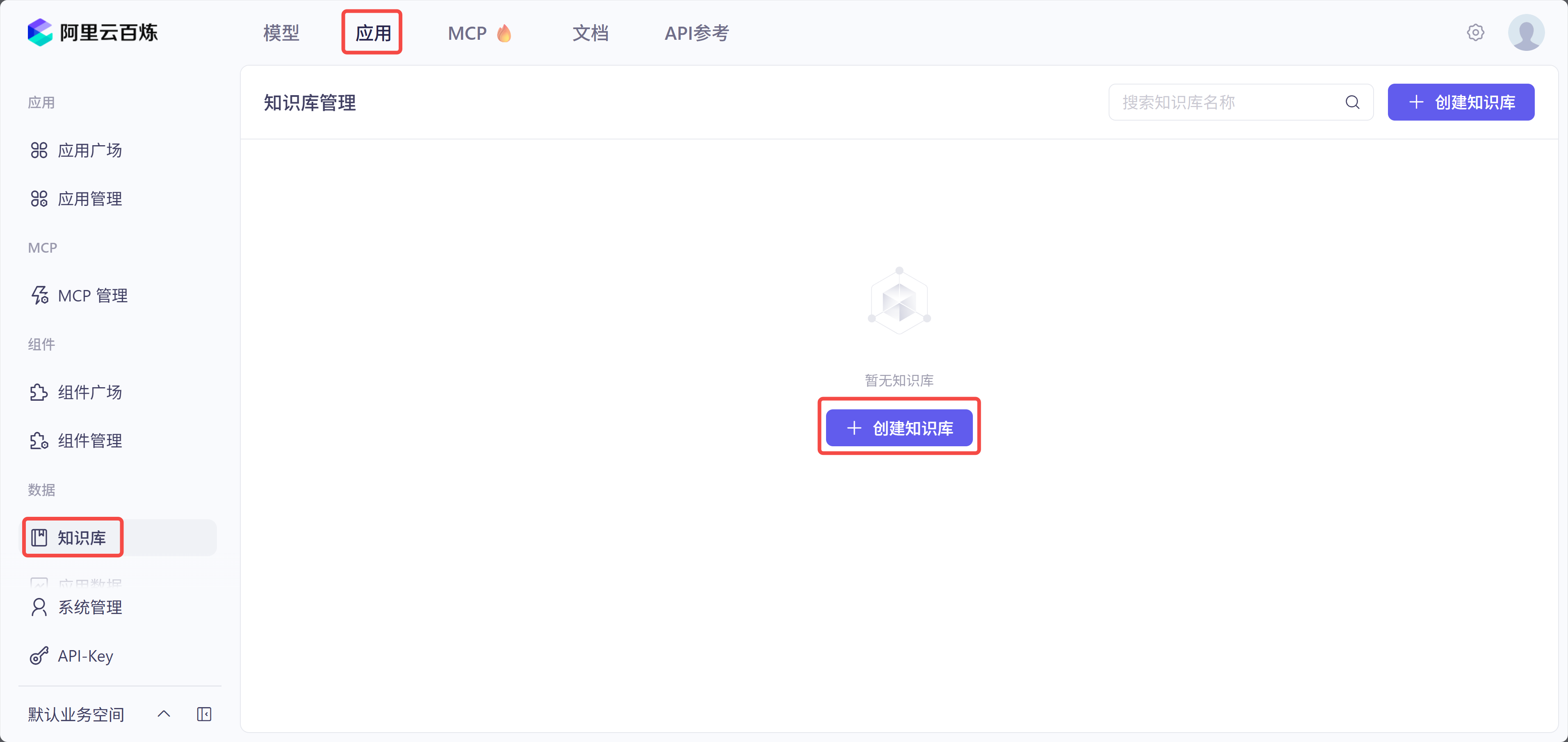
- 百炼创建知识库(https://bailian.console.aliyun.com/console?tab=app#/knowledge-base):
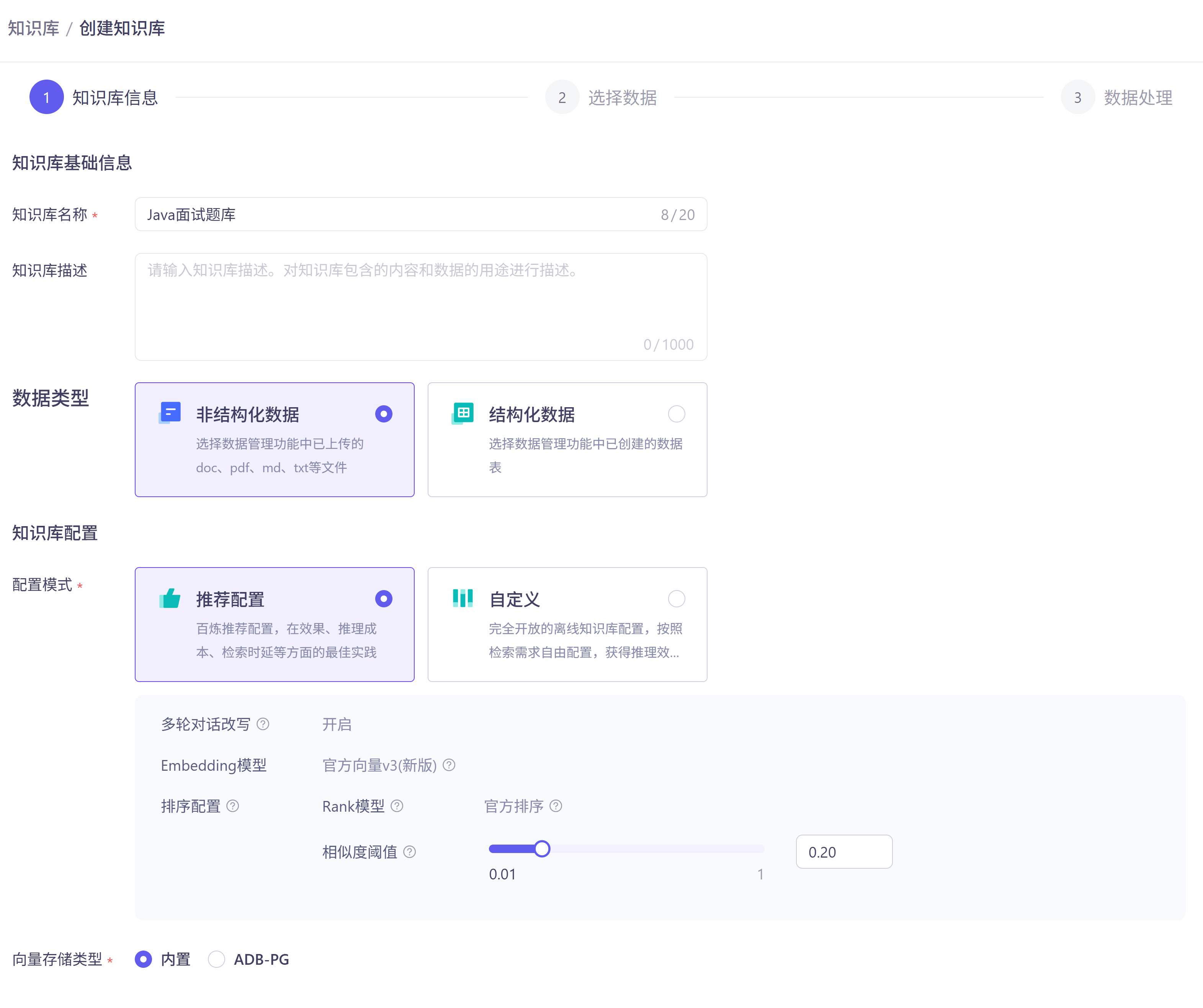
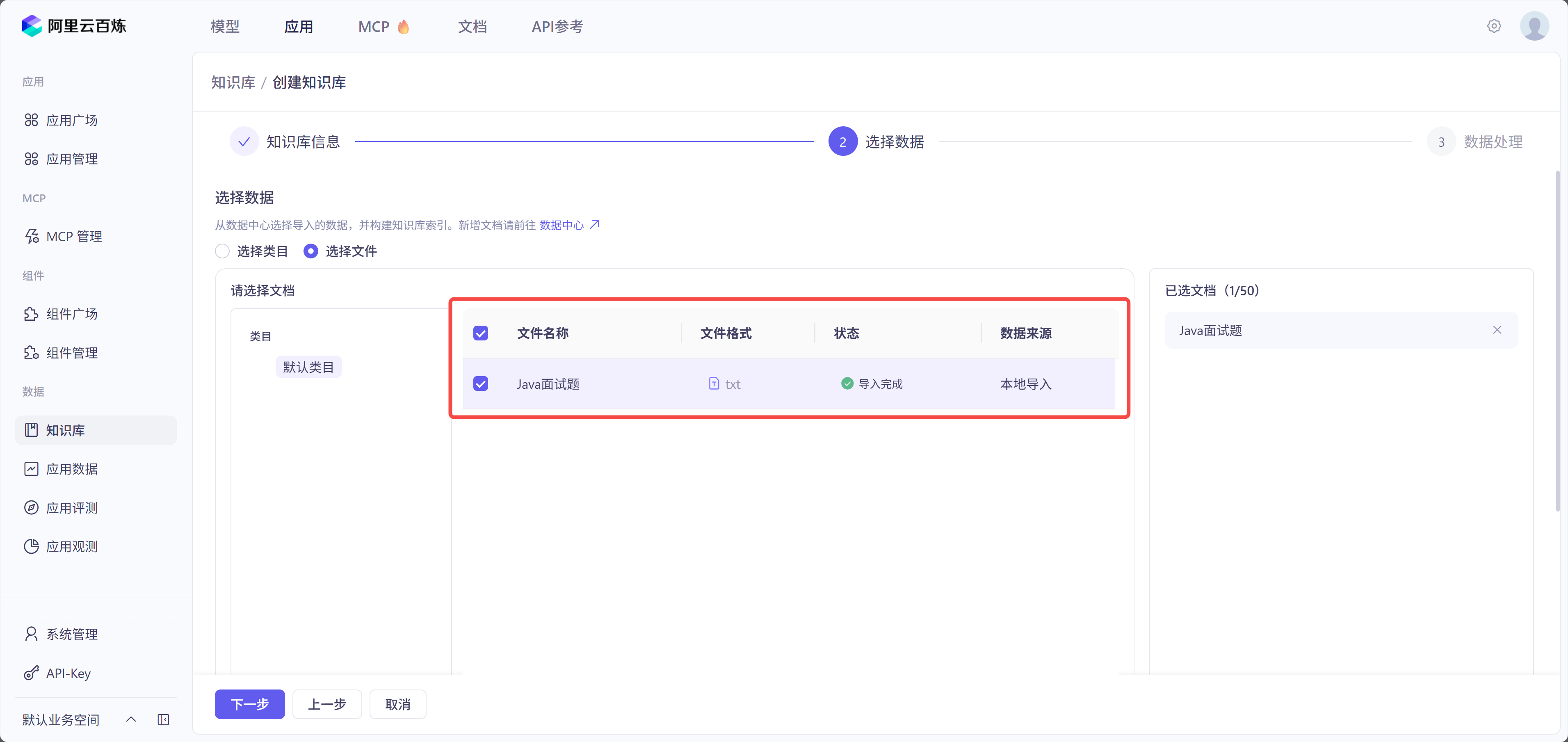
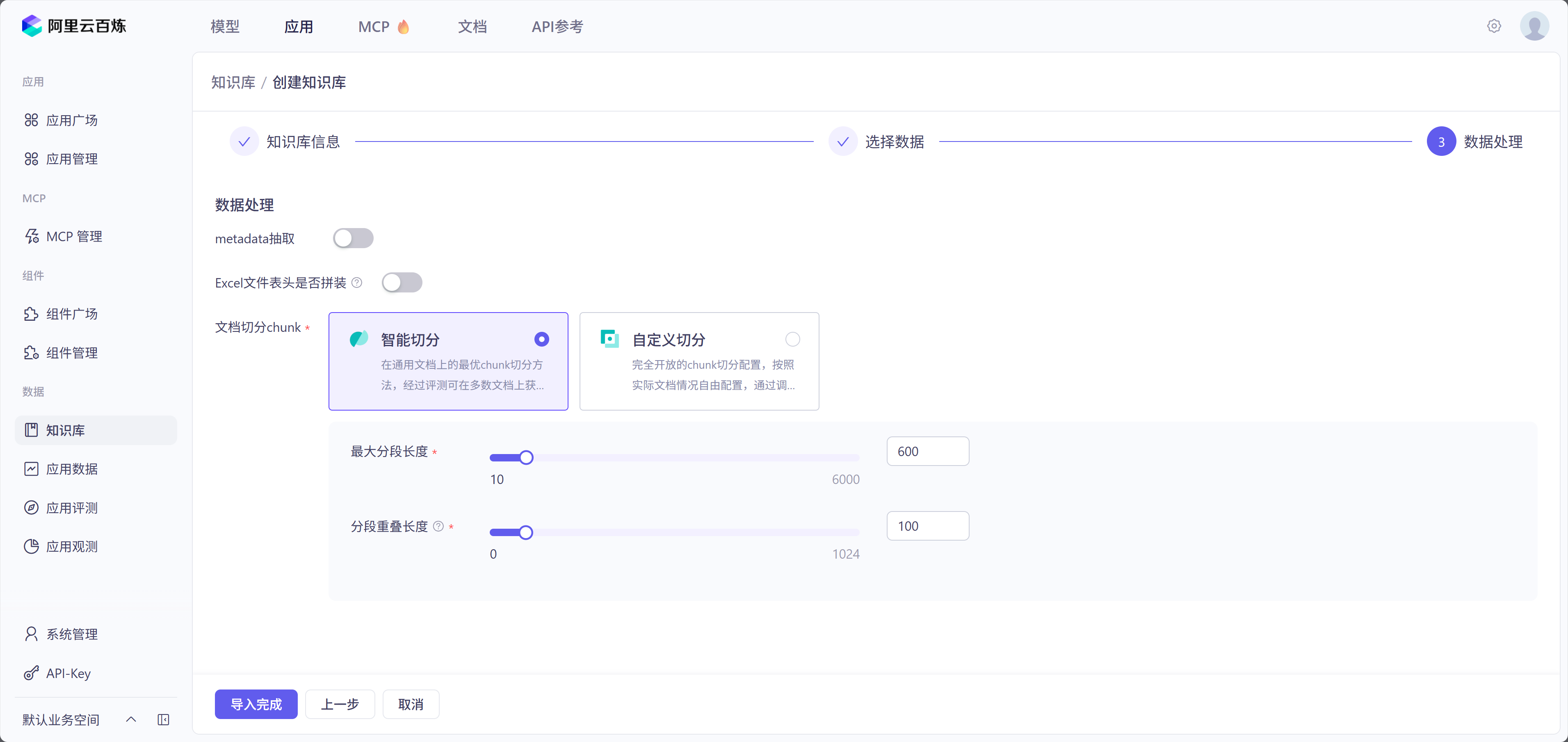

2.编写代码调用云知识库
编写代码操作云知识库
@RequestMapping("/rag")
public Flux<String> rag(@RequestParam String msg) {
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder().withIndexName(indexName).build());
return chatClient.prompt()
.system("你是一个Java助手,基于知识库的内容进行回答,知识库查询不到的信息,返回暂无信息")
.user(msg)
.advisors(new DocumentRetrievalAdvisor(retriever))
.stream().content();
}
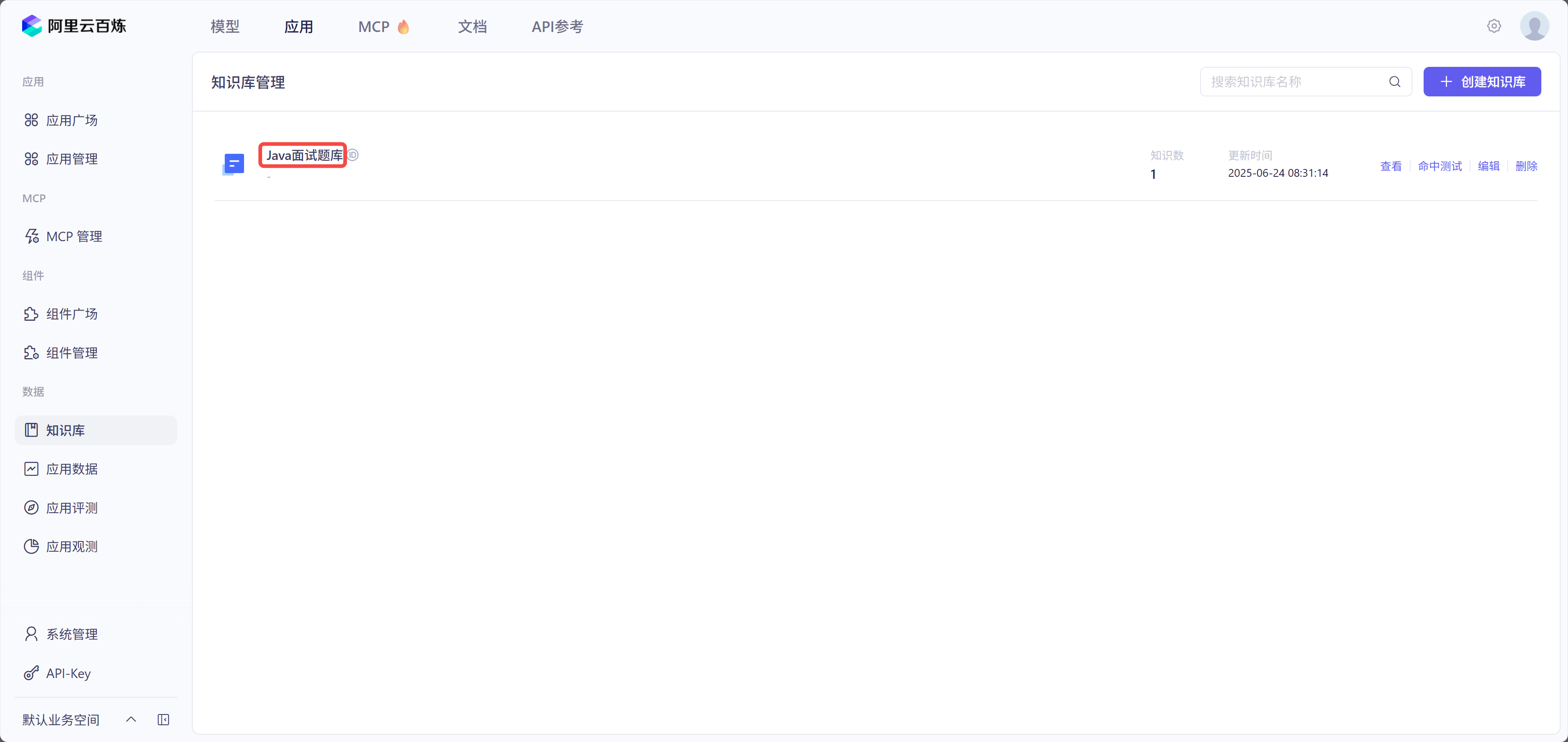
其中 indexName 为知识库的名字,如下图所示:
小结
本地 Spring AI Alibaba 程序可以直接调用百炼平台的云知识库,实现知识库文档解析、分块、向量化存储等一条龙服务,大大提升 RAG 开发的效率,但同时也会带来数据隐私问题,所以我们需要根据自己的业务选择合适的方案。
特殊说明
以上内容来自我的《AI大模型应用开发》 系列课,这些课程为视频+图文版,深入浅出学习了大模型应用开发的各种技术,例如系统学习了 LangChain、N8N、Python、Spring AI、Spring AI Alibaba、LangChain4j、Dify、Agent、AI 实战项目、AI 常见面试题等,其中包含:MCP、Function Call、RAG(简单、原生、高级应用)、向量数据库(Milvus、RedisStack)、Prompt工程、多模态、向量数据库、嵌入模型、100+ AI 实战案例。手把手教你快速、系统掌握大模型应用开发的核心技术。
如果对此课程感兴趣,请加我微信:vipStone【备注:LLM】
